
* I’ve been using LLMs heavily, daily for the past few years.I must add I am also using them on my own machine, I recommend people try Dwarfstar (ds4), https://github.com/antirez/ds4. That all said one thing has been bugging me, every time I get a little further than I did with the previous model, but I never ever manage to finish anything without having to spend a great deal of effort. These models have been sold that they could replace people technical people, who needs an architect, developer or tester when you can just get these models to create or do what you want? Theres also plenty of people ‘one shotting’ things, bah!, the latest models will have hoovered up github so will have everything they need to create minecraft/counterstrike/doom but they wont be able to create something brand new, something novel.
** This is a bit techie.
*** My views are my own, etc… please add your own views and comments.
For the past few years, the tech world has been locked in a collective state of anthropomorphic vertigo. We’ve treated Large Language Models like digital prophets, personal confidants, and embryonic deities. Venture capital has flowed like water into any startup promising a monolithic, multi-trillion-parameter “God-in-a-box” capable of achieving Artificial General Intelligence (AGI) through the sheer, brute force of next-token prediction.
But if you strip away the marketing gloss, the smooth chat interfaces, and the sci-fi branding, you are left with a sobering mathematical reality: an LLM is essentially a hyper-advanced autocomplete engine. It is a lossy, compressed, high-dimensional statistical database with a natural language interface.
It doesn’t “know” that a dropped wine glass will shatter because of the laws of physics and gravitational acceleration; it merely knows that within its training corpus, the tokens “dropped glass” and “shattered shards” share an intimate probabilistic proximity.
We haven’t built a thinking mind. We have built Knowledge Base 2.0. And just like the brittle Knowledge Bases of the 1980s, this architectural paradigm is running headfirst into an unforgiving glass ceiling.
The Rebrand: From SQL Joins to Latent Spaces
To understand why LLMs are hitting a wall, it helps to look at the ancestral lineage of enterprise data structures. A generation ago, we built Knowledge Base 1.0. These were our SQL databases, our graph databases, and the infamous “Expert Systems” of the late-20th-century AI boom.
Knowledge Base 1.0 was built on explicit, rigid rules. It relied on hand-coded `IF-THEN` statements, strict schemas, and deterministic logic. If you wanted a system to diagnose a medical condition or route a financial transaction, a human “knowledge engineer” had to painstakingly map out every single edge case in an XML schema or a relational table.
The system was perfectly precise, but it was catastrophically brittle. A single missing semicolon, an unmapped keyword, or a minor typo in an API payload would cause the entire system to throw a 500 error and collapse. It had zero tolerance for the messy, ambiguous chaos of human reality.
[Knowledge Base 1.0] ──► Rigid Input Parsing ──► Relational Tables ──► Deterministic Output (Brittle)
[Knowledge Base 2.0] ──► Semantic Input Parsing ──► Vector Weights ──► Probabilistic Output (Fluid)
Knowledge Base 2.0 flips this dynamic on its head. Instead of storing facts in rigid tables, an LLM compresses the collective text of human history into billions of floating-point numbers (weights).
This allows for an indestructible input parser. You can feed a modern frontier model slang, broken grammar, typos, or abstract analogies, and it will effortlessly decipher your meaning. Why? Because it maps your messy input into a fluid vector space where concepts are clusters of mathematical probabilities rather than hardcoded rows.
The miracle of Knowledge Base 2.0 is interpolation—the ability to smoothly blend ideas that already exist within its training data. It is why you can ask it to write a Python script that automates a spreadsheet in the literary style of William Shakespeare, and it will deliver a flawlessly formatted output. It feels like creative problem-solving. In reality, the model is merely traversing a highly likely path through its compressed version of GitHub and the Folger Library, retrieving and morphing patterns that statistically align with your prompt.
But this brings us to the fatal flaw of the interpolation engine: it cannot extrapolate.
An LLM operates strictly within the convex hull of its training data. It can synthesize, summarize, and cross-reference everything humanity has already discovered, but it cannot step out into the dark to find something fundamentally new. It can write an elegant paper summarizing existing oncology research, but it cannot sit at a laboratory bench, observe a novel cellular mutation, deduce a completely new biological law, and invent a cure.
Think of an LLM as a giant, multi-gigabyte JPEG of human knowledge. If you zoom out, the picture looks breathtakingly comprehensive. But if you zoom in too closely on a rare, highly specific, or novel edge case, the pixels begin to blur. The model fills in those blurry gaps with mathematical artifacts.
In the AI community, we call those artifacts “hallucinations.” In software engineering, we call them what they really are: an elegant retrieval failure.
The Ghost of AI Past: The Looming De-Hype Phase
If this story sounds familiar, it’s because we have watched this exact movie before. In the mid-1980s, corporations spent hundreds of millions of dollars deploying Expert Systems. The hype was unhinged. Prominent technologists declared that human expertise would soon be obsolete, locked away in corporate mainframes.
Then reality set in. The systems proved too expensive to maintain, too brittle to adapt to real-world changes, and entirely incapable of generalizing beyond their narrow domains. When the return on investment (ROI) evaporated, venture capital vanished overnight, triggering a devastating, multi-decade “AI Winter.”
Are we heading for another dark age?
The financial indicators are certainly terrifying. The current Capex vs. Revenue chasm is unsustainable. The world’s tech giants are on track to spend over a trillion dollars on infrastructure—buying up nuclear power plants, constructing gigawatt data centers, and hoarding tens of thousands of power-hungry GPUs—all to train models whose primary monetization strategy is selling $20-a-month consumer chat subscriptions or fractions of a cent per API token.
Enterprises that rushed to replace white-collar workflows with LLMs are experiencing the “Overwhelmed Intern” problem. They’ve realized that while a frontier model can summarize an annual report in three seconds, it cannot be trusted to execute a complex financial trade or file a legal brief without rigorous human supervision. When tasked with multi-step logic, the models stumble.
Furthermore, we are running out of high-quality human data to feed the pre-training maw, and attempts to train models on synthetic data (AI-generated text) are causing “model collapse”—an incestuous degradation where the neural network gradually forgets the nuances of human language.
A massive market correction is inevitable. Hundreds of “wrapper startups”—companies that are nothing more than a pretty user interface over someone else’s API—will go bankrupt. Tech stocks will correct sharply. The tourist capital will flee.
However, this correction won’t plunge us into a true AI Winter. The difference between 1988 and today lies in baseline utility. An 1980s Expert System was useless to 99% of the population. A modern LLM, even if its capabilities never improve by another single percentage point, is already a permanent, ubiquitous utility. It has fundamentally transformed coding, translation, semantic search, and copy generation. It is woven into our IDEs, our spreadsheets, and our operating systems.
We aren’t entering a Dark Age. We are entering the De-Hype Phase. The magical thinking is dying, and the era of actual systems engineering is beginning.
The Barbell Strategy and Jevons’ Paradox
As the industry accepts that monolithic pre-training scaling laws are hitting diminishing returns, the technical landscape is splitting into a fascinating “barbell strategy.” Innovation is no longer focused purely on making one giant model smarter; it is moving aggressively toward the two extremes of the compute spectrum.
On one end of the barbell, we are seeing the aggressive crushing of compute requirements via Small Language Models (SLMs). Thanks to techniques like model distillation (using giant models to curate pristine training data for smaller ones) and quantization (compressing 32-bit weights down to 4-bit precision), models ranging from 1B to 14B parameters are now matching the capabilities of yesteryear’s cloud giants. These models run locally, entirely offline, on consumer hardware and edge devices with negligible memory footprints and sub-100-millisecond latencies. For 80% of everyday software tasks, compute needs are plummeting.
On the other end of the barbell, the demand for frontier-grade compute remains insatiable, driven by a pivot from *Pre-training Compute* to *Test-Time Compute* (or Inference-Time Scaling).
[Traditional LLM] ──► Prompt ──► Next-Token Prediction ──► Instant Response
[Reasoning Model] ──► Prompt ──► Internal MCTS / RL Loops ──► Self-Correction ──► Long-Horizon Output
Instead of a model instantly spitting out the next most likely token, modern reasoning architectures utilize reinforcement learning and Monte Carlo Tree Search (MCTS) to allow the model to “think before it speaks.” When faced with a complex scientific, mathematical, or coding problem, the system enters an internal execution loop. It generates hypotheses, tests them against structural rules, discovers errors, corrects its own logic, and tries again.
A query to a future AI scientist won’t take two seconds; it might run for six hours, consuming immense compute as it iterates through thousands of internal variations before delivering a verified breakthrough.
This divergence is governed by Jevons’ Paradox—an economic principle stating that as technological progress increases the efficiency with which a resource is used, the total consumption of that resource tends to *rise* rather than fall, because it becomes cheaper, more accessible, and more widely integrated.
By making basic tokens incredibly cheap and efficient, we haven’t reduced the world’s hunger for compute. Instead, we have unlocked the economic viability of Multi-Agent Systems.
The Rise of the Cognitive OS
Because a single LLM cannot discover anything genuinely new, the future of AI architecture has shifted from a single “brain” to an orchestration triumph. To solve real problems, we are building ecosystems where a central reasoning model acts as a conductor leading an orchestra of highly specialized domain specific models, deterministic validators, and sandboxed code execution environments.
This shift has forced the hand of the major labs. They realized that selling raw intelligence (tokens) is a race to the bottom with zero margin. To survive, they must own the orchestration layer—the Cognitive Operating System.
This is why Anthropic open-sourced the Model Context Protocol (MCP). It wasn’t an act of pure altruistic developer love; it was a brilliant strategic move to establish the open-standard “USB-C port” for AI integration. By creating a standardized architecture for how a model exposes tools, queries databases, and interacts with enterprise files, they are trying to position their models as the central router of the corporate tech stack.
Similarly, OpenAI’s aggressive internal shift toward multi-agent frameworks and long-horizon execution loops demonstrates that the value proposition has shifted from *knowledge retrieval* to *autonomous labor*.
In this landscape, legacy tech titans—most notably Google—sit on a mountain of structural real estate. An orchestrator is only as valuable as the endpoints it is allowed to control. While startups must build complex, friction-filled API bridges to access corporate data, Google natively owns the entire stack: the enterprise data layer (BigQuery), the productivity suite (Workspace), the browser (Chrome), and the mobile operating system (Android). They don’t just have a great conductor; they own the concert hall, the ticket booth, and the instruments.
Enterprise Service Bus 2.0: The Ultimate Architectural Trap
But here is where the story takes a dark, deeply ironic turn for those of us who have spent decades navigating enterprise software architecture.
When you look closely at the design patterns of this new Cognitive Operating System—where a central cognitive hub routes natural language prompts, transforms them into structured API payloads, calls specialized external tools, aggregates the data, and passes it along to the next endpoint—you realize something terrifying.
We haven’t built a new cognitive paradigm. We have accidentally rebuilt the Enterprise Service Bus (ESB). Welcome to ESB 2.0.
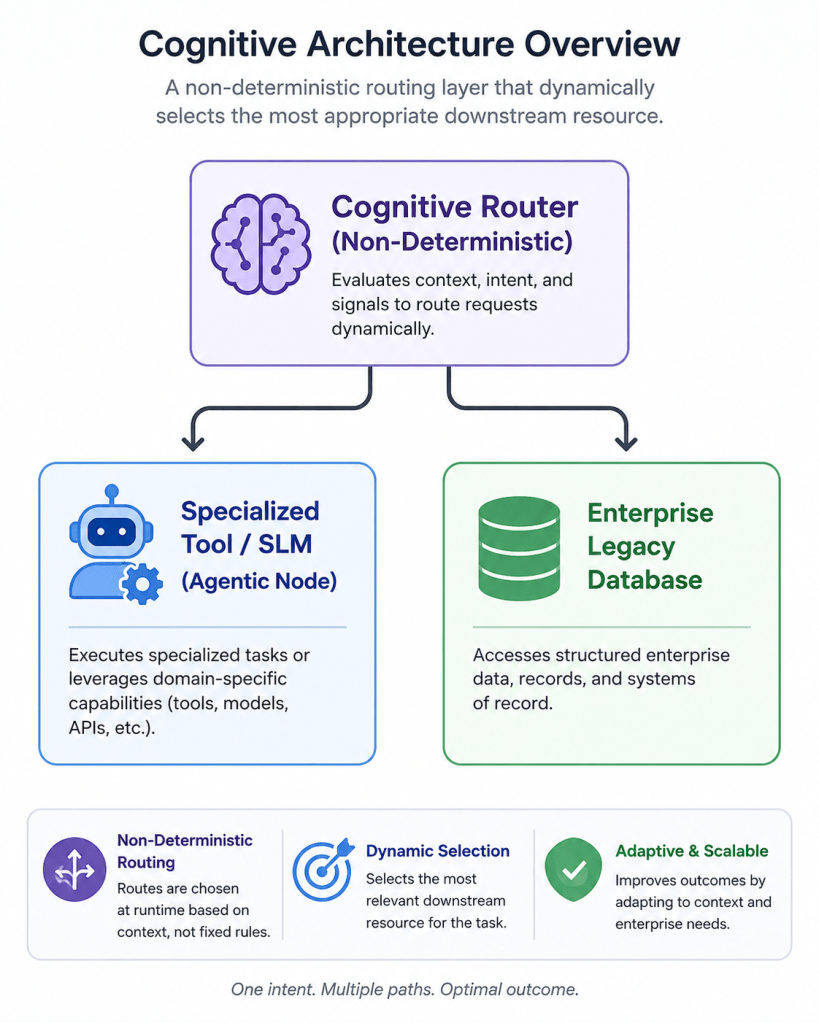
For those who managed to block out the trauma of the mid-2000s Service-Oriented Architecture (SOA) boom, the ESB was a centralized middleware layer designed to seamlessly connect decoupled, legacy systems. It promised to handle message routing, protocol translation (converting XML to JSON to SOAP), and complex workflow orchestration on the fly.
The ESB promised absolute enterprise harmony. Instead, it became a bloated, monolithic nightmare that cost corporations millions of dollars in specialized consulting fees to maintain.
The original ESB failed because it violated the core architectural law of distributed systems design: “Smart endpoints, dumb pipes.” Instead of keeping the integration pipe simple and leaving the business logic at the endpoints, the ESB swallowed the business logic whole. It became an incredibly complex, brittle, single point of failure. If you changed a single data mapping rule inside the bus, ten downstream systems would break silently.
With ESB 2.0, we are violating this rule on an unprecedented scale. Not only are we making the integration pipe smart—we are making it non-deterministically smart.
Consider the implications for an enterprise workflow:
1. The Prompt Psychiatry Crisis
In ESB 1.0, if an integration broke, it was frustrating but traceable. You could look at the transformation logic, realize an XML schema had changed, adjust the mapping rule, and re-deploy. The system was deterministic.
In ESB 2.0, your routing and transformation logic is handled by the fluid latent space of an LLM. If the model provider pushes a silent update over the weekend that alters the model’s attention weights, your orchestrator might suddenly change its mind on step 4 of a critical 10-step supply chain workflow.
The integration fails silently, or worse, outputs data that looks plausible but is fundamentally corrupted. Debugging this doesn’t involve looking at stack traces; it requires “prompt psychiatry”—vaguely guessing how to re-word a system instruction to coax the model back into compliance.
2. The Return of the Integration Tax
We are witnessing the rapid emergence of a new consultant cash-cow. Just as the 2000s gave rise to highly paid WebSphere and TIBCO integration architects, the modern era is creating an army of “AI Transformation Consultants,” “Semantic Graph Engineers,” and “Agentic System Designers.” We are rebuilding the exact same integration tax, just wrapped in a cooler, vector-infused vocabulary.
The Lone Saving Grace
Is ESB 2.0 doomed to the exact same failure as its predecessor? Not necessarily. It possesses one unique superpower that the original middleware era never had: resilience to semantic chaos.
The original ESB was brittle because it lived in a binary world. If an underlying legacy system updated its API schema and changed a field name from `user_id` to `customer_identifier`, the traditional bus would throw an exception, reject the payload, and halt the production line. It lacked the capacity to reason about intent.
A cognitive orchestrator, however, operates on semantic intent. It looks at the mutated payload, evaluates the context of the workflow, realizes that `customer_identifier` and `user_id` represent the exact same underlying entity within this specific operational boundary, maps them on the fly, and keeps the system running smoothly. It trades absolute predictability for unprecedented adaptability.
The tech giants have realized that the standalone LLM is a rapidly depreciating commodity. The real monopoly—and the real trillions—lies in owning the middleware. Google, Microsoft, and Amazon aren’t fighting to sell you the smartest model anymore; they are fighting to become the Enterprise Service Bus of the modern age.
If they succeed, they will lock enterprises into their cloud ecosystems for the next thirty years—not because their models can think, but because their non-deterministic pipes are hooked into every single database, application, and screen in your building.
As engineers, architects, and builders, our job isn’t to worship the intelligence of the bus. Our job is to build the guardrails, the verification loops, and the deterministic sanity checks required to ensure that when our new, fuzzy middleware decides to orchestrate the enterprise, it doesn’t accidentally hallucinate the company into a brick wall.





Leave a comment